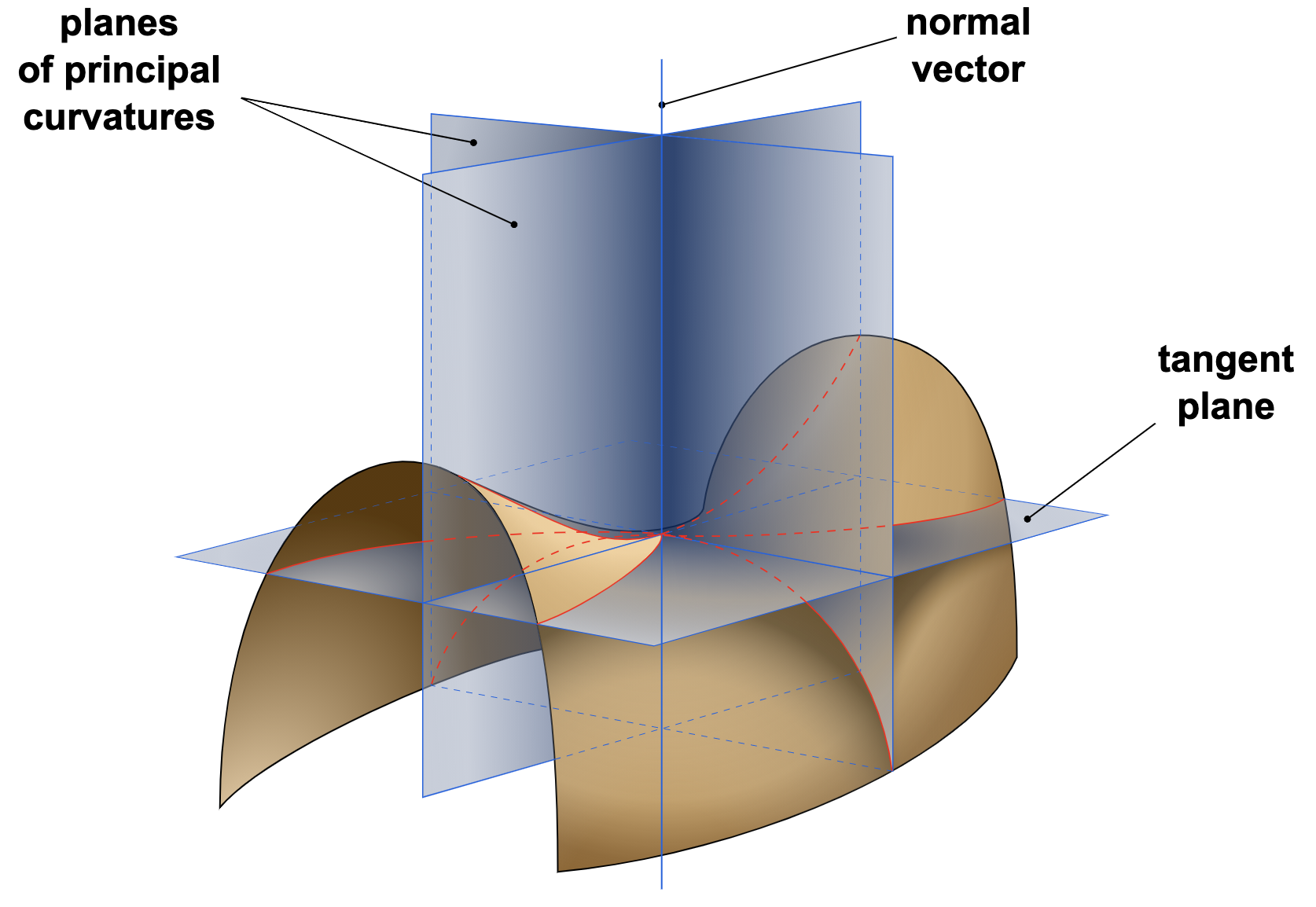
Elementary Differential Geometry
Instructor, TU Graz.
As of March 2024 I have left the TU Graz.
This is my old academic website, which might at some point go through a major overhaul if it is to attempt to represent me:).

Up until recently I was an Assistant Professor at the Institute for Geometry of the Department of Mathematics at TU Graz, Austria.
My research background is in geometric modeling, computer graphics, and computer vision. Prior to joining TU Graz, I was a postdoctoral mathematics researcher at the TU Berlin, with the Institute for Geometry and Mathematical Physics. I have worked at Autodesk Research, San Francisco as a principal AI researcher with the Machine Intelligence Lab, and at Stanford University as a postdoctoral CS researcher with the Geometric Computing Lab. My PhD was with the Interactive Geometry Lab of the CS department at ETH Zurich, Switzerland. I have a Master's in CS from ETH Zurich, having worked with the Computer Vision and Geometry Group. My undergraduate (Diploma) work was with the Computer Vision and Signal Processing Group at the National Technical University of Athens, Greece. I've been an intern for the Adobe Research Labs in Cambridge MA, and Disney Research Zurich.
My current research interests lie in applied geometry, somewhere between geometry processing, (discrete) differential geometry, projective geometry, shape modeling/analysis for computer graphics and computational design. I have however also worked in various topics involving shape analysis, meshing, discrete surface maps and parameterization, image synthesis and computational fabrication, and have also been active in projects in geometric machine learning for object detection and generation, dynamic scene understanding from RGBD sensing, and 3D reconstruction.

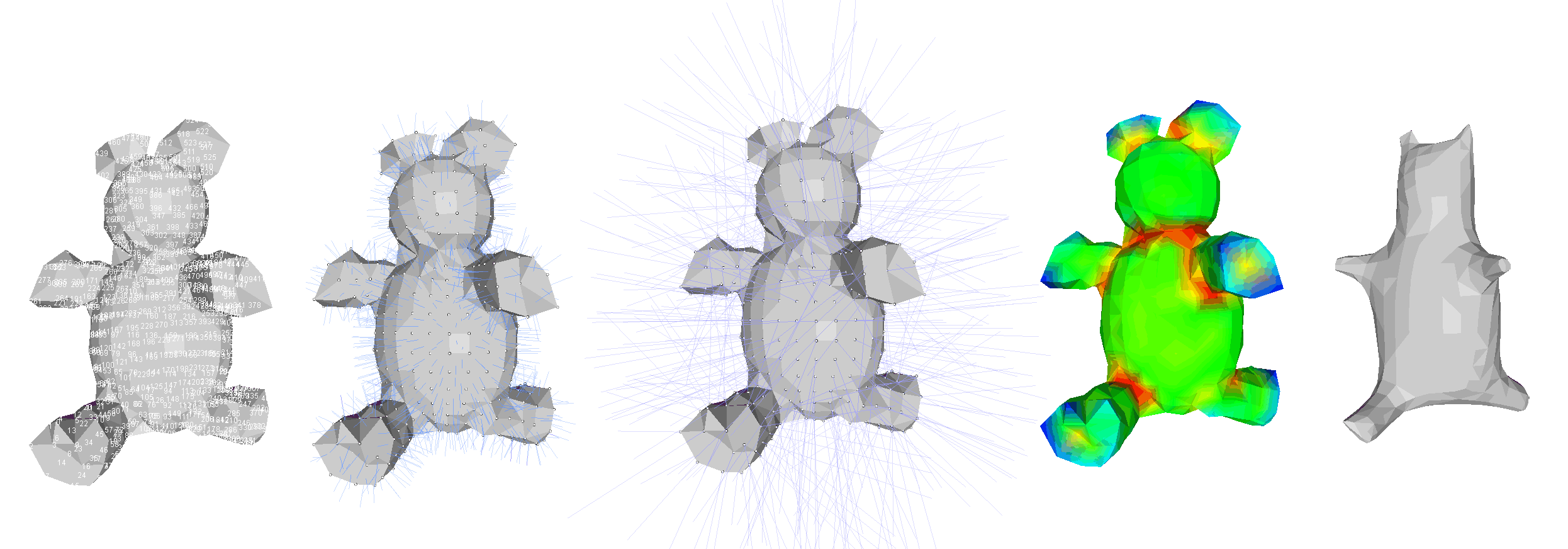
Strip-decomposable quadrilateral (SDQ) meshes, i.e., quad meshes that can be decomposed into two transversal strip networks, are vital in numerous fabrication processes; examples include woven structures, surfaces from sheets, custom rebar, or cable-net structures. However, their design is often challenging and includes tedious manual work, and there is a lack of methodologies for editing such meshes while preserving their strip decomposability. We present an interactive methodology to generate and edit SDQ meshes aligned to user-defined directions, while also incorporating desirable properties to the strips for fabrication. Our technique is based on the computation of two coupled transversal tangent direction fields, integrated into two overlapping networks of strips on the surface. As a case study, we consider the fabrication scenario of robotic non-planar 3D printing of free-form surfaces and apply the presented methodology to design and fabricate non-planar print paths.

Smooth curves and surfaces can be characterized as minimizers of squared curvature bending energies subject to constraints. In the univariate case with an isometry (length) constraint this leads to classic non-linear splines. For surfaces, isometry is too rigid a constraint and instead one asks for minimizers of the Willmore (squared mean curvature) energy subject to a conformality constraint. We present an efficient algorithm for (conformally) constrained Willmore surfaces using triangle meshes of arbitrary topology with or without boundary. Our conformal class constraint is based on the discrete notion of conformal equivalence of triangle meshes. The resulting non-linear constrained optimization problem can be solved efficiently using the competitive gradient descent method together with appropriate Sobolev metrics. The surfaces can be represented either through point positions or differential coordinates. The latter enable the realization of abstract metric surfaces without an initial immersion. A versatile toolkit for extrinsic conformal geometry processing, suitable for the construction and manipulation of smooth surfaces, results through the inclusion of additional point, area, and volume constraints.
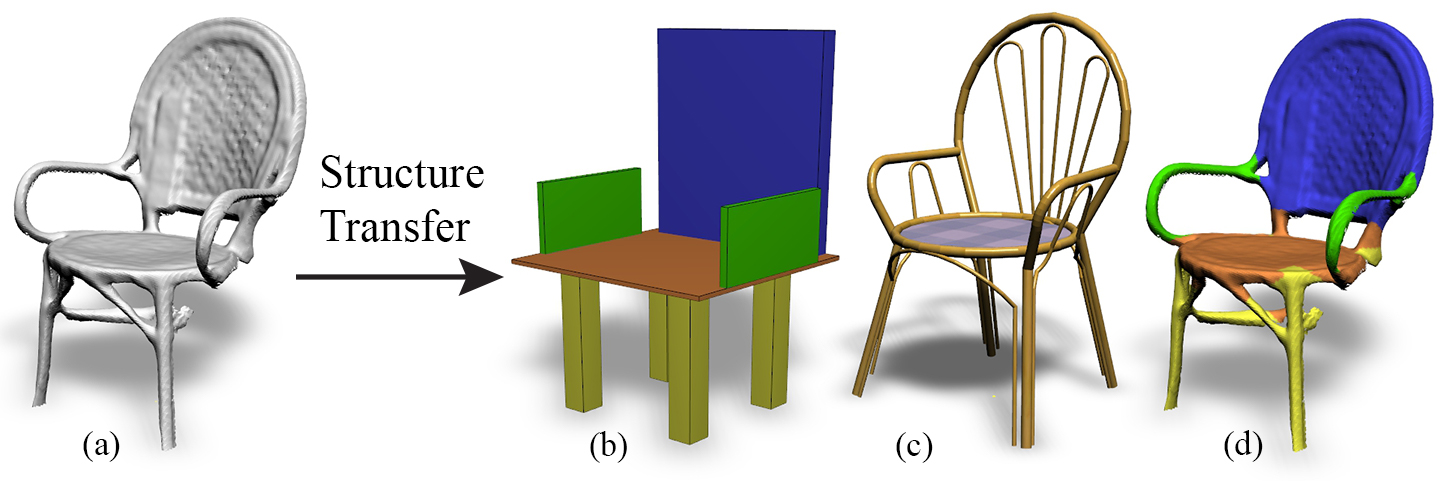
Real-life man-made objects often exhibit strong and easily-identifiable structure, as a direct result of their design or their intended functionality. Structure typically appears in the form of individual parts and their arrangement. Knowing about object structure can be an important cue for object recognition and scene understanding - a key goal for various AR and robotics applications. However, commodity RGB-D sensors used in these scenarios only produce raw, unorganized point clouds, without structural information about the captured scene. Moreover, the generated data is commonly partial and susceptible to artifacts and noise, which makes inferring the structure of scanned objects challenging. In this paper, we organize large shape collections into parameterized shape templates to capture the underlying structure of the objects. The templates allow us to transfer the structural information onto new objects and incomplete scans. We employ a deep neural network that matches the partial scan with one of the shape templates, then match and fit it to complete and detailed models from the collection. This allows us to faithfully label its parts and to guide the reconstruction of the scanned object. We showcase the effectiveness of our method by comparing it to other state-of-the-art approaches.

Spectral mesh analysis and processing methods, namely ones that utilize eigenvalues and eigenfunctions of linear operators on meshes, have been applied to numerous geometric processing applications. The operator used predominantly in these methods is the Laplace-Beltrami operator, which has the often-cited property that it is intrinsic, namely invariant to isometric deformation of the underlying geometry, including rigid transformations. Depending on the application, this can be either an advantage or a drawback. Recent work has proposed the alternative of using the Dirac operator on surfaces for spectral processing. The available versions of the Dirac operator only focus on the extrinsic version – however, often a trade-off between the Laplace and Dirac operators is needed. A recent attempt to introduce a range of Dirac-like operators on a spectrum between fully intrinsic and extrinsic produces operators that only loosely relate to Dirac and, importantly, do not relate to conformal surface deformations of the surface, as one would expect from the Dirac operator. In this work, we introduce a unified discretization scheme that describes both an extrinsic and intrinsic Dirac operator on meshes, based on their continuous counterparts on smooth manifolds. In this discretization, both operators are very closely related, and preserve their key properties from the smooth case. We showcase various applications of our operators, with improved numerics over prior work.
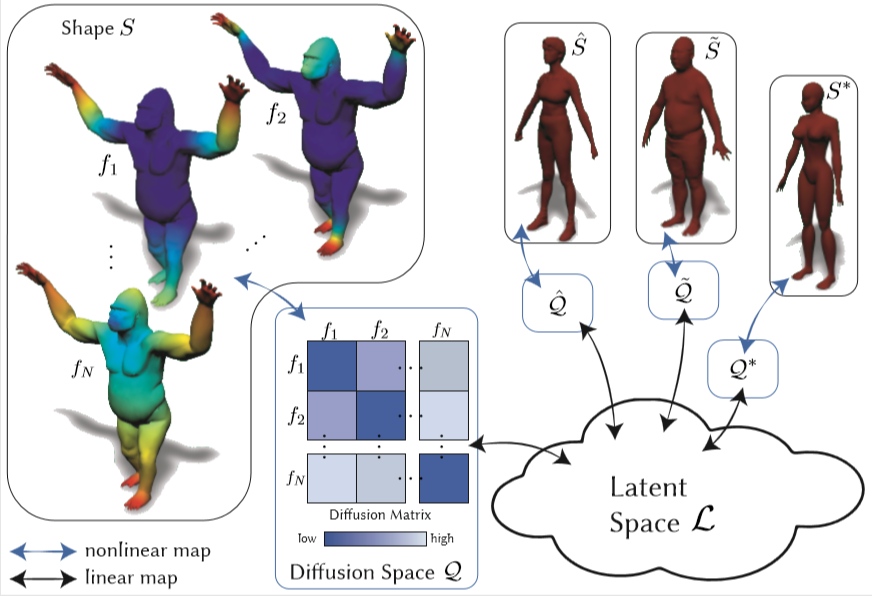
We consider the problem of transporting shape descriptors across shapes in a collection in a modular fashion, in order to establish correspondences between them. A common goal when mapping between multiple shapes is consistency, namely that compositions of maps along a cycle of shapes should be approximately an identity map. Existing attempts to enforce consistency typically require recomputing correspondences whenever a new shape is added to the collection, which can quickly become in- tractable. Instead, we propose an approach that is fully modular, where the bulk of the computation is done on each shape independently. To achieve this, we use intermediate nonlinear embedding spaces, computed individually on every shape; the embedding functions use ideas from diffusion geometry and capture how different descriptors on the same shape inter-relate. We then establish linear mappings between the different embedding spaces, via a shared latent space. The introduction of nonlinear embeddings allows for more nuanced correspondences, while the modularity of the construction allows for paral- lelizable calculation and efficient addition of new shapes. We compare the performance of our framework to standard functional correspondence techniques and showcase the use of this framework to simple interpolation and extrapolation tasks.

Three-dimensional geometric data offer an excellent domain for studying repre- sentation learning and generative modeling. In this paper, we look at geometric data represented as point clouds. We introduce a deep autoencoder (AE) network with excellent reconstruction quality and generalization ability. The learned repre- sentations outperform the state of the art in 3D recognition tasks and enable basic shape editing applications via simple algebraic manipulations, such as semantic part editing, shape analogies and shape interpolation. We also perform a thorough study of different generative models including: GANs operating on the raw point clouds, significantly improved GANs trained in the fixed latent space our AEs and Gaussian mixture models (GMM). Interestingly, GMMs trained in the latent space of our AEs produce samples of the best fidelity and diversity. To perform our quantitative evaluation of generative models, we propose simple measures of fidelity and diversity based on optimally matching between sets point clouds.

Three-dimensional geometric data offer an excellent domain for studying representation learning and generative modeling. In this paper, we look at geometric data represented as point clouds. We introduce a deep auto-encoder (AE) network for point clouds, which outperforms the state of the art in 3D recognition tasks. We also design GAN architectures to generate novel point-clouds. Most importantly, we show that by training the GAN in the latent space learned by the AE, we greatly boost the GAN’s data-generating capacity, creating significantly more diverse and realistic geometries, with far simpler architectures. The expressive power of our learned embedding, obtained without human supervision, enables basic shape editing applications via simple algebraic manipulations, such as semantic part editing and shape interpolation.

Many real-world tasks for autonomous agents benefit from understanding dynamic inter-object interactions. Detecting, analyzing and differentiating between the various ways that an object can be interacted with provides implicit information about its function. This can help train autonomous agents to handle objects and understand unknown scenes. We describe a general mathematical framework to analyze and classify interactions, defined as dynamic motions performed by an active object onto a passive one. We factorize interactions via motion features computed in the spatio-temporal domain, and encoded into a global, object-centric signature. Equipped with a similarity measure to compare such signatures, we showcase classification of interactions with a single object. We also propose a novel acquisition setup combining RGBD sensing with a virtual reality (VR) display, to capture interactions with purely virtual objects.
Direction fields and vector fields play an increasingly important role in computer graphics and geometry processing. The synthesis of directional fields on surfaces, or other spatial domains, is a fundamental step in numerous applications, such as mesh generation, deformation, texture mapping, and many more. The wide range of applications resulted in definitions for many types of directional fields: from vector and tensor fields, over line and cross fields, to frame and vector-set fields.
Depending on the application at hand, researchers have used various notions of objectives and constraints to synthesize such fields. These notions are defined in terms of fairness, feature alignment, symmetry, or field topology, to mention just a few. To facilitate these objectives, various representations, discretizations, and optimization strategies have been developed. These choices come with varying strengths and weaknesses.
This report provides a systematic overview of directional field synthesis for graphics applications, the challenges it poses, and the methods developed in recent years to address these challenges.

Computing mappings between spaces is a very general problem that appears in various forms in geometry processing. They can be used to provide descriptions or representations of shapes, or place shapes in correspondence. Their applications range from surface modeling and analysis to shape matching, morphing, attribute transfer and deformation.
This thesis addresses two particular mapping problems that are of interest in the field, namely inter-surface maps and parameterizations. We focus on methods that are suitable for user-guided applications - we do not consider automatic methods, that do not leave space for the user to control the result. Existing methods for the particular sub-problems that we are studying often either suffer from performance limitations, or cannot guarantee that the produced results align with the user's intent; we improve upon the state of the art in both those respects.
The first problem we study in this thesis is that of inter-surface mapping, with given sparse landmark point correspondences. We found that an efficient solution to this otherwise difficult topic emerges if one reformulates the mapping problem as a problem of finding affine combinations of points on the involved shapes. We extend the notion of standard Euclidean weighted averaging to 3D manifold shapes, and introduce a fast approximation that can be used to solve this problem much faster than the state of the art. We showcase applications of this approach in interactive attribute transfer between shapes.
Next, we move on to the problem of surface parameterization. Here, we study the problem from the application point of view of surface remeshing; a popular way to generate a quadrilateral mesh for a given triangular mesh is to first compute a global parameterization, which is guided by a tangent vector field. This field then determines the directions of the quadrilateral edges on the output mesh. In order to design such a direction field, recent methods to tackle the problem are based on integer optimization problems, which often suffer from slow performance and local minima. We reformulate the problem in a way that the field design problem becomes a linear problem. We also add more flexibility by allowing for non-orthogonal directions.
Still on the same problem of field-aligned surface parameterizations, we notice that the standard way of producing fields --namely, an optimization only focused on field smoothness-- does not necessarily guarantee that the resulting quadrilateral meshing will be what the user intended in terms of edge directions. This is due to errors introduced in the post-processing of the field, during the later stages of the remeshing pipeline. This renders such fields suboptimal for user-guided meshing applications. We extend our efficient reformulation of the field design problem to generate fields that are guaranteed to not introduce such further errors, and thus make sure that the users obtain the expected results. Additionally, we allow users more flexible control, by supporting assignment of partial constraints for only some of the directions.

In the digital world, assigning arbitrary colors to an object is a simple operation thanks to texture mapping. However, in the real world, the same basic function of applying colors onto an object is far from trivial. One can specify colors during the fabrication process using a color 3D printer, but this does not apply to already existing objects. Paint and decals can be used during post-fabrication, but they are challenging to apply on complex shapes. In this paper, we develop a method to enable texture mapping of physical objects, that is, we allow one to map an arbitrary color image onto a three-dimensional object. Our approach builds upon hydrographics, a technique to transfer pigments printed on a sheet of polymer onto curved surfaces. We first describe a setup that makes the traditional water transfer printing process more accurate and consistent across prints. We then simulate the transfer process using a specialized parameterization to estimate the mapping between the planar color map and the object surface. We demonstrate that our approach enables the application of detailed color maps onto complex shapes such as 3D models of faces and anatomical casts.

We present a framework for designing curl-free tangent vector fields on discrete surfaces. Such vector fields are gradients of locally-defined scalar functions, and this property is beneficial for creating surface parameterizations, since the gradients of the parameterization coordinate functions are then exactly aligned with the designed fields. We introduce a novel definition for discrete curl between unordered sets of vectors (PolyVectors), and devise a curl-eliminating continuous optimization that is independent of the matchings between them. Our algorithm naturally places the singularities required to satisfy the user-provided alignment constraints, and our fields are the gradients of an inversion-free parameterization by design.

Editing materials in photos opens up numerous opportunities like turning an unappealing dirt ground into luscious grass and creating a comfortable wool sweater in place of a cheap t-shirt. However, such edits are challenging. Approaches such as 3D rendering and BTF rendering can represent virtually everything, but they are also data intensive and computationally expensive, which makes user interaction difficult. Leaner methods such as texture synthesis are more easily controllable by artists, but also more limited in the range of materials that they handle, for example, grass and wool are typically problematic because of their non-Lambertian reflectance and numerous self-occlusions. We propose a new approach for editing of complex materials in photographs. We extend the texture-by-numbers approach with ideas from texture interpolation. The inputs to our method are coarse user annotation maps that specify the desired output, such as the local scale of the material and the illumination direction. Our algorithm then synthesizes the output from a discrete set of annotated exemplars. A key component of our method is that it can cope with missing data, interpolating information from the available exemplars when needed. This enables production of satisfying results involving materials with complex appearance variations such as foliage, carpet, and fabric from only one or a couple of exemplar photographs.

This paper describes human classifiers that are 'viewpoint specific', meaning specific to subjects being observed by a particular camera in a particular scene. The advantages of the approach are (a) improved human detection in the presence of perspective foreshortening from an elevated camera, (b) ability to handle partial occlusion of subjects e.g. partial occlusion by furniture in an indoor scene, and (c) ability to detect subjects when partially truncated at the top, bottom or sides of the image. Elevated camera views will typically generate truncated views for subjects at the image edges but our viewpoint specific method handles such cases and thereby extends overall detection coverage. The approach is - (a) define a tiling on the ground plane of the 3D scene, (b) generate training images per tile using virtual humans, (c) train a classifier per tile (d) run the classifiers on the real scene. The approach would be prohibitive if each new deployment required real training images, but it is feasible because training is done with a virtual humans inserted into a scene model. The classifier is a linear SVM and HOGs. Experimental results provide a comparative analysis with existing algorithms to demonstrate the advantages described above.
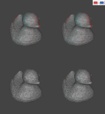
A pervasive artifact that occurs when visualizing 3D content is the so-called "cardboarding" effect, where objects appear flat due to depth compression, with relatively little research conducted to perceptually quantify its effects. Our aim is to shed light on the subjective preferences and practical perceptual limits of stereo vision with respect to cardboarding. We present three experiments that explore the consequences of displaying simple scenes with reduced depths using both subjective ratings and adjustments and objective sensitivity metrics. Our results suggest that compressing depth to 80% or above is likely to be acceptable, whereas sensitivity to the cardboarding artifact below 30% is very high. These values could be used in practice as guidelines for commonplace depth mapping operations in 3D production pipelines.
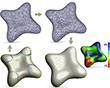
We introduce N-PolyVector fields, a generalization of N-RoSy fields for which the vectors are neither necessarily orthogonal nor rotationally symmetric. We formally define a novel representation for N-PolyVectors as the root sets of complex polynomials and analyze their topological and geometric properties. A smooth N-PolyVector field can be efficiently generated by solving a sparse linear system without integer variables. We exploit the flexibility of N-PolyVector fields to design conjugate vector fields, offering an intuitive tool to generate planar quadrilateral meshes.

We consider the problem of generalizing affine combinations in Euclidean spaces to triangle meshes: computing weighted averages of points on surfaces. We address both the forward problem, namely computing an average of given anchor points on the mesh with given weights, and the inverse problem, which is computing the weights given anchor points and a target point. Solving the forward problem on a mesh enables applications such as splines on surfaces, Laplacian smoothing and remeshing. Combining the forward and inverse problems allows us to define a correspondence mapping between two different meshes based on provided corresponding point pairs, enabling texture transfer, compatible remeshing, morphing and more. Our algorithm solves a single instance of a forward or an inverse problem in a few microseconds. We demonstrate that anchor points in the above applications can be added/removed and moved around on the meshes at interactive framerates, giving the user an immediate result as feedback.

The goal of a markerless motion algorithm is to recover the pose of a person from a set of images or videos. This is typically addressed in two ways: global optimization, used primarily when pose detection is the main interest, and/or local optimization, when the focus is on pose tracking. While the latter can provide very accurate results in relatively little time, it suffers from sensitivity to local minima. On the contrary, the former approach ensures a correct estimation of the pose, even without any prior pose information, at the cost of much higher computational complexity.
This thesis addresses the pose detection problem in both these ways by enhancing an already existing tracking approach so as to obtain a robust motion capture algorithm. This allows us to track people also in not controlled environments, such as in the case of outdoor scenarios. Additionally, we incorporate appearance modeling (by means of a texture map) with the aim to improve the tracking results.

Reliable segmentation and motion tracking algorithms are required to achieve gesture detection and tracking for human-machine interaction. In this paper we present an efficient method for detecting and tracking moving hands in sign language video frames. We make use of the geodesic active region framework in conjunction with new color and motion forces; color information is provided by a skin color model, while motion information is derived from the optical flow field. Extensive experimentation indicates that the proposed algorithm behaves sufficiently well for gesture detection and tracking.
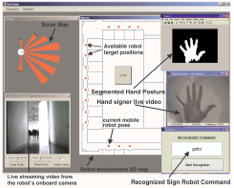
This paper presents results achieved in the frames of a national research project (titled DIANOEMA
), where visual analysis and sign recognition techniques have been explored on Greek Sign Language (GSL) data. Besides GSL modelling, the aim was to develop a pilot application for teleoperating a mobile robot using natural hand signs. A small vocabulary of hand signs has been designed to enable desktopbased teleoperation at a high-level of supervisory telerobotic control. Real-time visual recognition of the hand images is performed by training a multi-layer perceptron (MLP) neural network. Various shape descriptors of the segmented hand posture images have been explored as inputs to the MLP network. These include Fourier shape descriptors on the contour of the segmented hand sign images, moments, compactness, eccentricity, and histogram of the curvature. We have examined which of these shape descriptors are best suited for real-time recognition of hand signs, in relation to the number and choice of hand postures, in order to achieve maximum recognition performance. The hand-sign recognizer has been integrated in a graphical user interface, and has been implemented with success on a pilot application for real-time desktop-based gestural teleoperation of a mobile robot vehicle.

This paper presents the scientific framework and achieved results of the DIANOEMA project, in the framework of which visual analysis and sign recognition techniques have been explored on Greek Sign Language (GSL) data aiming at GSL modelling and a pilot application for robot teleoperation. The project’s accomplishments comprise the Greek Sign Language Corpus (GSLC) creation and annotation, video analysis algorithms for automatic visual detection and gesture tracking, a probabilistic recognition scheme for Automatic Sign Language Recognition from multiple cues, and the pilot application on teleoperation of a Mobile Robot Vehicle.

This work focuses on two of the research problems comprising automatic sign language recognition, namely robust computer vision techniques for consistent hand detection and tracking, while preserving the hand shape contour which is useful for extraction of features related to the handshape and a novel classification scheme incorporating Self-organizing maps, Markov chains and Hidden Markov Models. Geodesic Active Contours enhanced with skin color and motion information are employed for the hand detection and the extraction of the hand silhouette, while features extracted describe hand trajectory, region and shape. Extracted features are used as input to separate classifiers, forming a robust and adaptive architecture whose main contribution is the optimal utilization of the neighboring characteristic of the SOM during the decoding stage of the Markov chain, representing the sign class.

The goal of this thesis is to test, extend and develop methods for the implementation of a sign language recognition (SLR) system based on the visual analysis of sign language videos. This application is part of the more general research area referred to as "human-machine interaction", which is strongly related to the science and technology of Computer Vision. More specifically, this thesis focuses on all the stages that are required prior to the recognition phase of a SLE system, namely the image segmentation, motion tracking and deature extraction stages. Special effort was made to cope with one of the most commonly met problems in SLR, which is the vagueness introduces in cases of hand-hand or hand-face occlusions. In each stage, a variety of methods and techniques is explored, which were retrieved following an extensive search of the state-of-the-art literature. The overall system is to be used (in combination with the necessary recognition stage) in the construction of a real practical SLR system for the recognition of a set of Greek Sign Language signs, as part of the research project "DIANOEMA".
Selected Lectures and Teaching Assistance, Stanford University.